
{kind=link}

Small models are often blocked by poor instruction tuning, weak tool use formats, and missing governance. IBM AI team released Granite 4.0 Nano, a small model family that targets local and edge inference with enterprise controls and open licensing. The family includes 8 models in two sizes, 350M and about 1B, with both hybrid SSM and transformer variants, each in base and instruct. Granite 4.0 Nano series models are released under an Apache 2.0 license with native architecture support on popular runtimes like vLLM, llama.cpp, and MLX

What is new in Granite 4.0 Nano series?
Granite 4.0 Nano consists of four model lines and their base counterparts. Granite 4.0 H 1B uses a hybrid SSM based architecture and is about 1.5B parameters. Granite 4.0 H 350M uses the same hybrid approach at 350M. For maximum runtime portability IBM also provides Granite 4.0 1B and Granite 4.0 350M as transformer versions.
Architecture and training
The H variants interleave SSM layers with transformer layers. This hybrid design reduces memory growth versus pure attention, while preserving the generality of transformer blocks. The Nano models did not use a reduced data pipeline. They were trained with the same Granite 4.0 methodology and more than 15T tokens, then instruction tuned to deliver solid tool use and instruction following. This carries over strengths from the larger Granite 4.0 models to sub 2B scales.
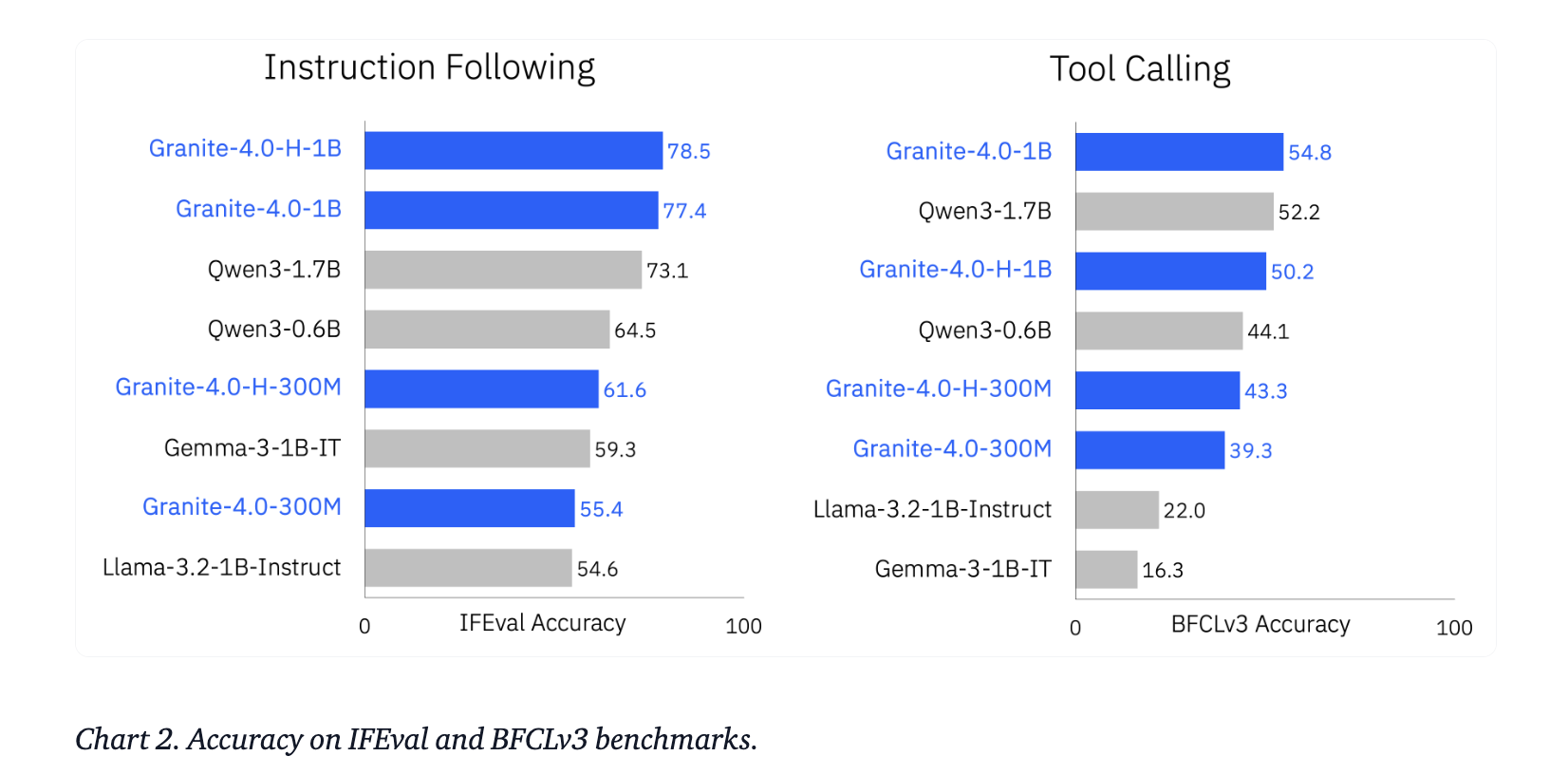
Benchmarks and competitive context
IBM compares Granite 4.0 Nano with other under 2B models, including Qwen, Gemma, and LiquidAI LFM. Reported aggregates show a significant increase in capabilities across general knowledge, math, code, and safety at similar parameter budgets. On agent tasks, the models outperform several peers on IFEval and on the Berkeley Function Calling Leaderboard v3.

Key Takeaways
IBM is doing the right thing here, it is taking the same Granite 4.0 training pipeline, the same 15T token scale, the same hybrid Mamba 2 plus transformer architecture, and pushing it down to 350M and about 1B so that edge and on device workloads can use the exact governance and provenance story that the larger Granite models already have. The models are Apache 2.0, ISO 42001 aligned, cryptographically signed, and already runnable on vLLM, llama.cpp and MLX. Overall, this is a clean and auditable way to run small LLMs.
Check out the Model Weights on HF and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.